塩漬けマンの株奮闘記
脱サラ農家が経済的フリーを目指して投資を始めるも、投機(マネーゲーム)に目覚めてしまい、日々投機を頑張り、ついに農業も辞めて専業投機家になってしまったブログです(`・ω・´)キリッ ただの備忘録日記ですので、銘柄を書いても、買い推奨ではありませんし、むしろ危険なので買わないで下さい。「株価の騰落は神のみぞ知る」で誰も分かりません。裁量トレードは大部分の人に取ってゼロサムゲームどころかマイナスゲームですのでやらない事をお勧めします(´・ω・`)しょぼーん
| ホーム |
2019-05-26 10:09 |
カテゴリ:勉強や投資情報
先週決算情報サイトを作ろうかなって書きましたが、色々事前調査をした結果、断念しました。
決算投資情報サイトでも作ろうかな
以下はSEでないと理解出来ないので、結果だけ言うと
XBRL使いづらいから無理!
って事です。
まず決算情報取得に利用しようとしたのがXBRLというXMLちっくな仕様で、EDINETやTDNETで有報や決算短信の決算データを電子利用しやすいような形式で提供する仕組みです。
しかし・・・これ・・・使えません。
まず、TDNETは過去一か月の情報しか保有しません・・・意味が分かりません。
この仕様を考えた担当者はデータの電子利用という意義を理解していません。
次にEDINETは過去全部のデータを取得出来るのはいいのですが、WEBスクレイピング(プログラムによる自動取得)は出来ないようになっています。
この仕様を考えた担当者はデータの電子利用という本質を理解していません。
尚、アメリカのSECが提供しているXBRLはFTPで一気に全データを取得可能で、本来こうあるべきです。
そこで諦めかけた所に気づいたのが有報キャッチャーという民間企業がやっているサービス。
過去のXBRLを保存・提供してくれているサービスです。
まず利用規約を読むと、XBRLはATOMというXMLベースで保存場所が提供されている模様。
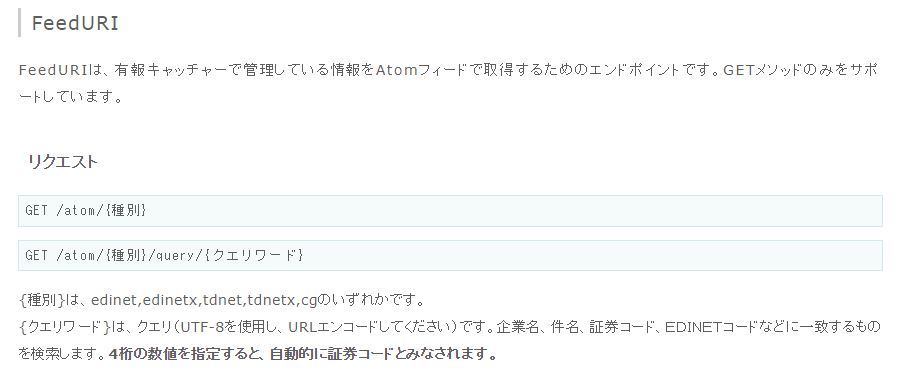
試しに上記の通りでWEBアクセスしてみると以下のように、確かにXMLっぽい感じで、XBRLデータへのアドレスが表示されました。
http://resource.ufocatch.com/atom/tdnet/query/6871

このファイルを全部見て精査すると、どうもhtmファイルに決算データがあり、ixタグのname属性で識別すればいい事が分かりました。
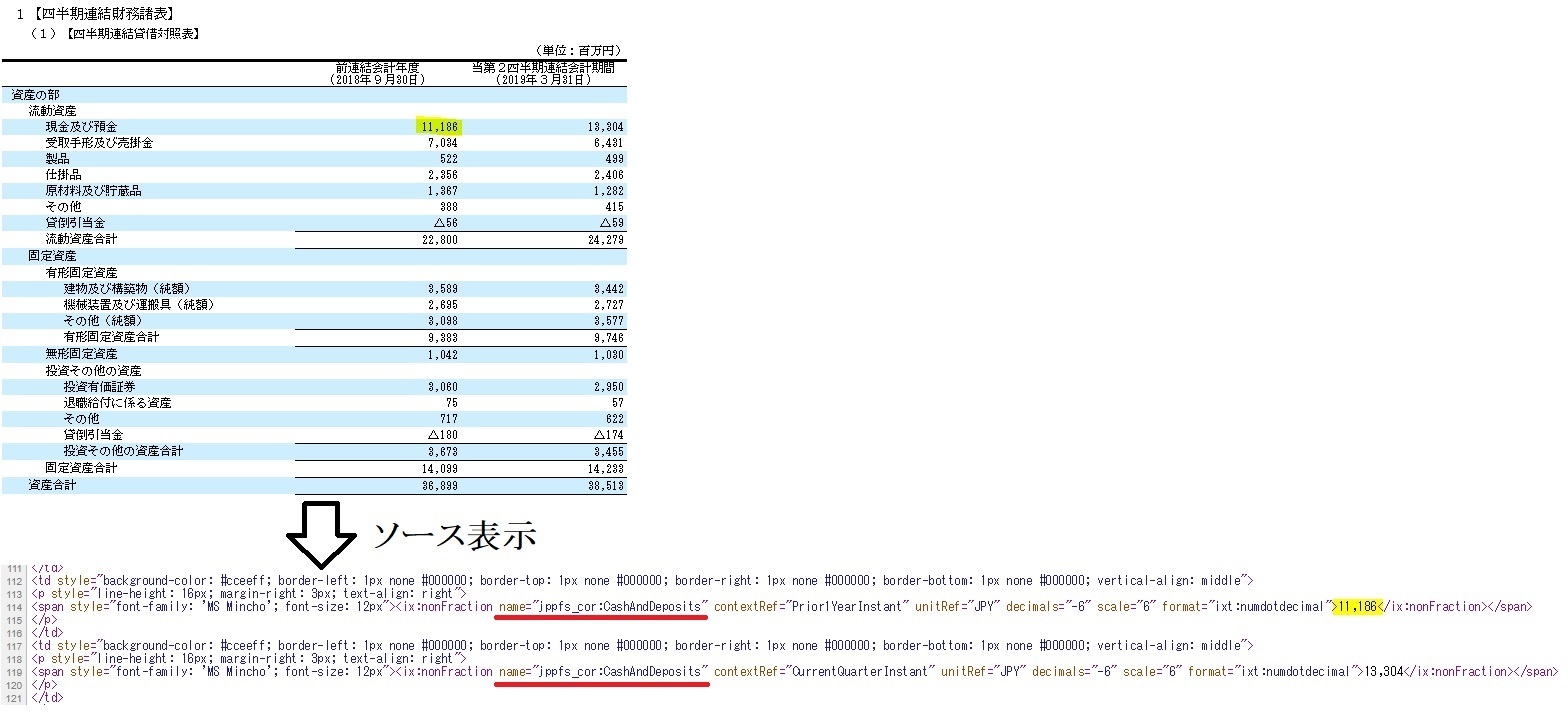
↓とりあえずVisualStudioでASPのプロジェクトを作って、コードの方はこんな感じで、とりあえずアドレス直書きで、アドレス先のXML(Atom)から決算情報の入ったhtmファイルのアドレスだけを取得するようにしました。これはデバック画面で、下の「ウォッチ1」を見たら分かる通り、listHttpに上記画像のhtmファイルへのアドレスだけが格納されています。aって変数はデバッグを一時停止するために入れてるだけです。
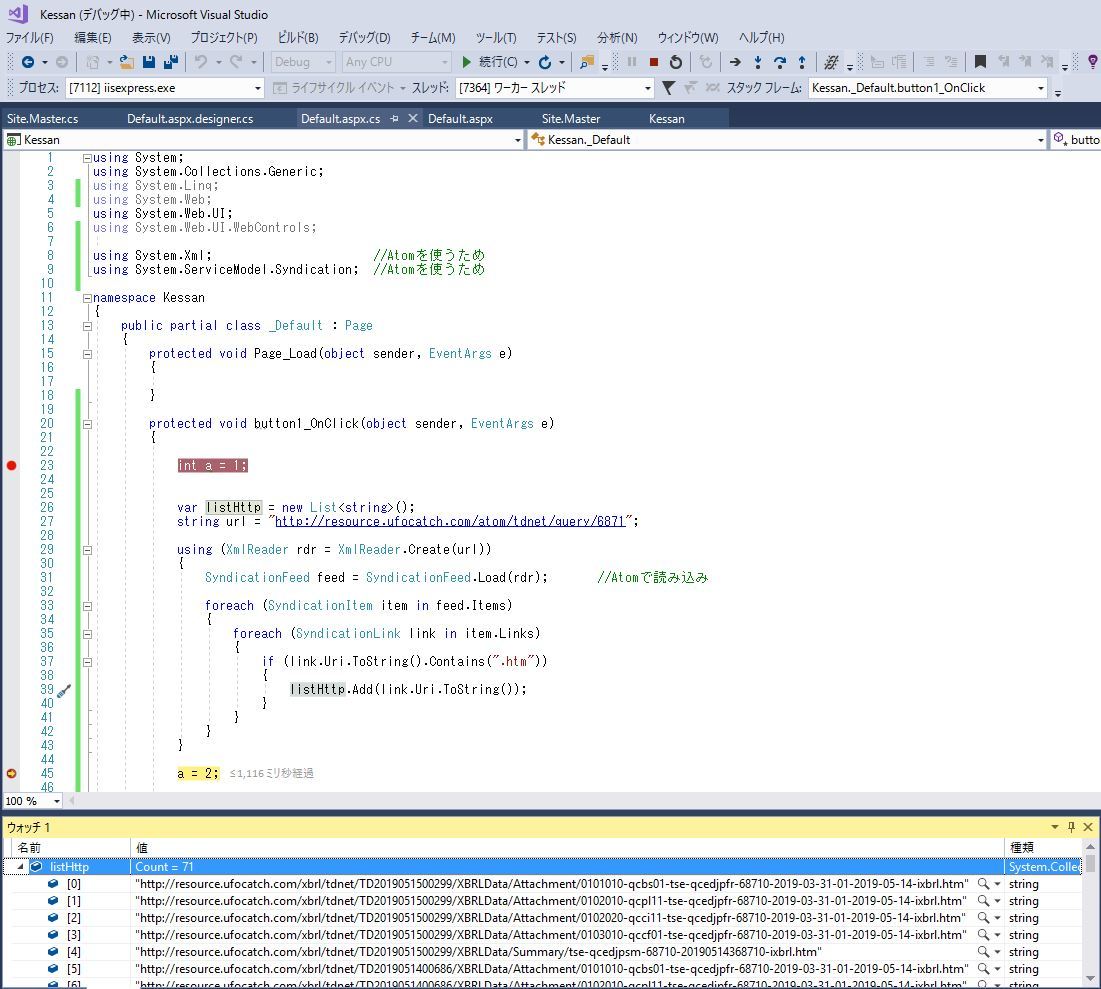
んで、いよいよhtmファイルから決算データを抜こうと思ったのですが・・・これが難しい!
htmファイルにhtmlとxmlが両方記載されてるってどういう事?
塩漬けマンがSE時代に勉強したXMLってそんな複雑だったっけ・・・
普通なら.netフレームワークではXDocumentクラスを使って簡単に出来るのですが、以下を見て貰ったら分かる通り、量が膨大で「長すぎて無理です」っていう見た事がない例外エラーが返されました。

ていうか、改行しろよっ!
上記画像で「ソース表示」で改行されてるのは有報の方です。決算短信の方はなんと、改行されていないので可読性ゼロですっ!
んで、とにかくixタグに必要なデータがあるのは分かっているので、ixタグ以外全削除して、ixタグのname属性を識別子にしてデータを取り出せるようにしました。
とにかく一つのデータを取り出そうとする度に問題が起きて、解決して次へ進んでいる時に・・・もう限界が来ました・・・
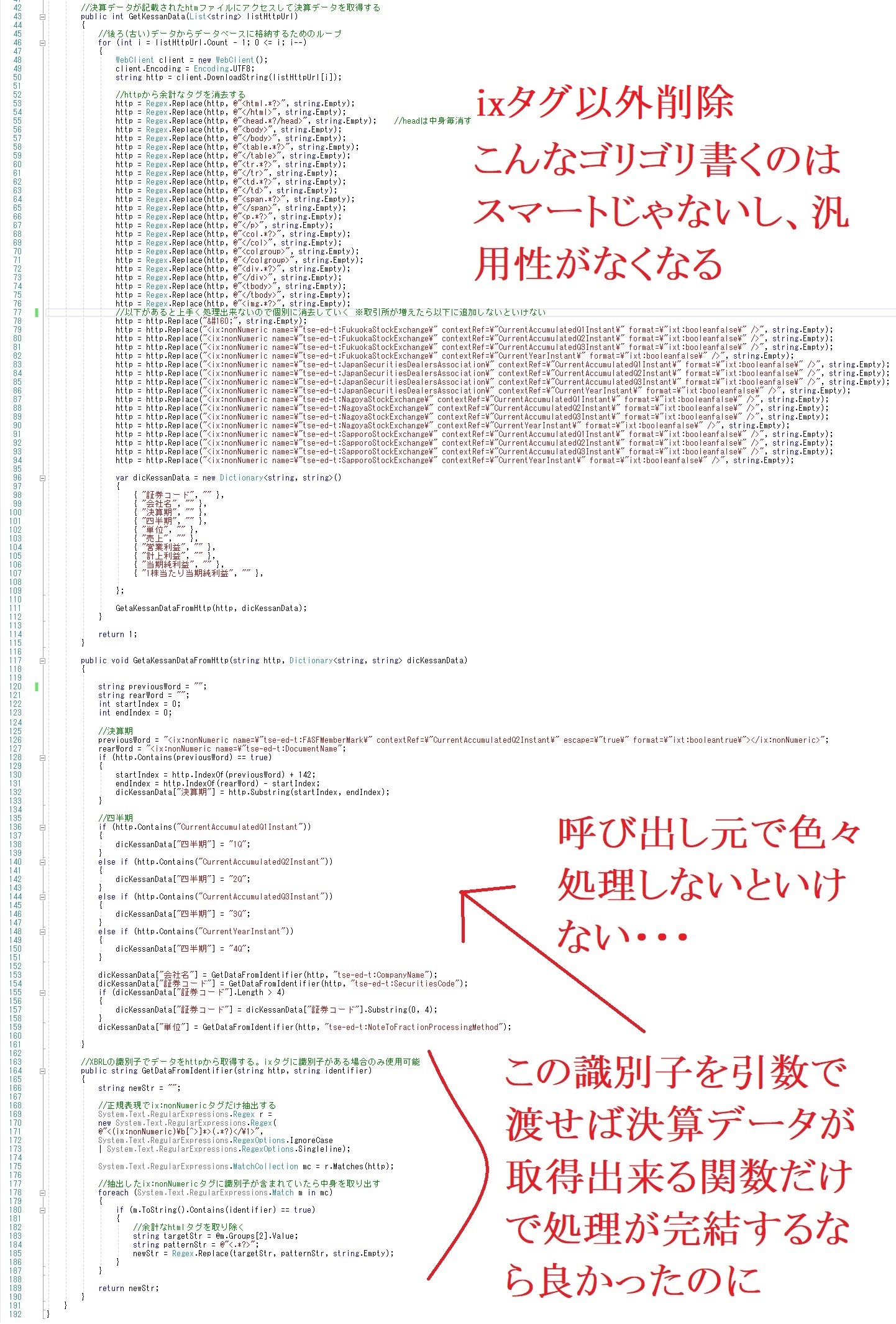
例えば売上データを識別するための識別子がtse-ed-t:NetSalesなのですが、それだけだと前期売上とか予想売上とかも抽出しちゃうので、contextRefって属性も見て、判断しないといけないのです。
↓一つのファイルにこれだけの種類の売上(tse-ed-t:NetSales)があるので、contextRef属性で判断が必要

一つ一つのデータ(コード、社名、決算期、売上等)取得するのに、何かしらそれぞれ異なる処理が必要(共通でないので共通関数化出来ない)です。
そうじゃなくて、キーを一つ投げたら、データが取得出来るのがデータベース(XML含む)の基本でしょ・・・
これ、XBRLの技術的な仕様書レベルから研究(勉強でなくて研究)しないと、どうやったら一意に効率的にデータを取得出来るのか分からないです。
ここでギブアップしました。
分かってます。XBRLは日本だけでなく国際的な統一規格だし、元がXMLなので、htmファイルだけでなく、xmlファイル・xsdファイルを使ってなんか上手くデータ取得出来るんだろうなって事は・・・でも塩漬けマンにはもう無理でした。
もう株探の決算でいいかな。
むしろ、やっちゃいけないんですけど、株探の決算のHPをWEBスクレイピングして、決算データを取得する方が多分楽です。
※多分個人でやる分には怒られませんが、そのデータで投資情報サイトを作って金儲けをしたら怒られます。
でもそれだと貸借対照表とかのデータがなくて、株探と同等になっちゃうので、やる意味もないですしね。
↓コメントはツイッターからどうぞ ※忙しいと申し訳ありませんが、コメント返信出来ない事があります。

↓応援クリックをして頂けたら感謝です。


↓拍手には特に意味はないのですが、ブログ内容の良し悪しパロメータとして使っています(´・ω・`)
決算投資情報サイトでも作ろうかな
以下はSEでないと理解出来ないので、結果だけ言うと
XBRL使いづらいから無理!
って事です。
まず決算情報取得に利用しようとしたのがXBRLというXMLちっくな仕様で、EDINETやTDNETで有報や決算短信の決算データを電子利用しやすいような形式で提供する仕組みです。
しかし・・・これ・・・使えません。
まず、TDNETは過去一か月の情報しか保有しません・・・意味が分かりません。
この仕様を考えた担当者はデータの電子利用という意義を理解していません。
次にEDINETは過去全部のデータを取得出来るのはいいのですが、WEBスクレイピング(プログラムによる自動取得)は出来ないようになっています。
この仕様を考えた担当者はデータの電子利用という本質を理解していません。
尚、アメリカのSECが提供しているXBRLはFTPで一気に全データを取得可能で、本来こうあるべきです。
そこで諦めかけた所に気づいたのが有報キャッチャーという民間企業がやっているサービス。
過去のXBRLを保存・提供してくれているサービスです。
まず利用規約を読むと、XBRLはATOMというXMLベースで保存場所が提供されている模様。

試しに上記の通りでWEBアクセスしてみると以下のように、確かにXMLっぽい感じで、XBRLデータへのアドレスが表示されました。
http://resource.ufocatch.com/atom/tdnet/query/6871

このファイルを全部見て精査すると、どうもhtmファイルに決算データがあり、ixタグのname属性で識別すればいい事が分かりました。

↓とりあえずVisualStudioでASPのプロジェクトを作って、コードの方はこんな感じで、とりあえずアドレス直書きで、アドレス先のXML(Atom)から決算情報の入ったhtmファイルのアドレスだけを取得するようにしました。これはデバック画面で、下の「ウォッチ1」を見たら分かる通り、listHttpに上記画像のhtmファイルへのアドレスだけが格納されています。aって変数はデバッグを一時停止するために入れてるだけです。

んで、いよいよhtmファイルから決算データを抜こうと思ったのですが・・・これが難しい!
htmファイルにhtmlとxmlが両方記載されてるってどういう事?
塩漬けマンがSE時代に勉強したXMLってそんな複雑だったっけ・・・
普通なら.netフレームワークではXDocumentクラスを使って簡単に出来るのですが、以下を見て貰ったら分かる通り、量が膨大で「長すぎて無理です」っていう見た事がない例外エラーが返されました。

ていうか、改行しろよっ!
上記画像で「ソース表示」で改行されてるのは有報の方です。決算短信の方はなんと、改行されていないので可読性ゼロですっ!
んで、とにかくixタグに必要なデータがあるのは分かっているので、ixタグ以外全削除して、ixタグのname属性を識別子にしてデータを取り出せるようにしました。
とにかく一つのデータを取り出そうとする度に問題が起きて、解決して次へ進んでいる時に・・・もう限界が来ました・・・

例えば売上データを識別するための識別子がtse-ed-t:NetSalesなのですが、それだけだと前期売上とか予想売上とかも抽出しちゃうので、contextRefって属性も見て、判断しないといけないのです。
↓一つのファイルにこれだけの種類の売上(tse-ed-t:NetSales)があるので、contextRef属性で判断が必要

一つ一つのデータ(コード、社名、決算期、売上等)取得するのに、何かしらそれぞれ異なる処理が必要(共通でないので共通関数化出来ない)です。
そうじゃなくて、キーを一つ投げたら、データが取得出来るのがデータベース(XML含む)の基本でしょ・・・
これ、XBRLの技術的な仕様書レベルから研究(勉強でなくて研究)しないと、どうやったら一意に効率的にデータを取得出来るのか分からないです。
ここでギブアップしました。
分かってます。XBRLは日本だけでなく国際的な統一規格だし、元がXMLなので、htmファイルだけでなく、xmlファイル・xsdファイルを使ってなんか上手くデータ取得出来るんだろうなって事は・・・でも塩漬けマンにはもう無理でした。
もう株探の決算でいいかな。
むしろ、やっちゃいけないんですけど、株探の決算のHPをWEBスクレイピングして、決算データを取得する方が多分楽です。
※多分個人でやる分には怒られませんが、そのデータで投資情報サイトを作って金儲けをしたら怒られます。
でもそれだと貸借対照表とかのデータがなくて、株探と同等になっちゃうので、やる意味もないですしね。
↓コメントはツイッターからどうぞ ※忙しいと申し訳ありませんが、コメント返信出来ない事があります。
↓応援クリックをして頂けたら感謝です。
↓拍手には特に意味はないのですが、ブログ内容の良し悪しパロメータとして使っています(´・ω・`)
| ホーム |
